


目标
在学习K8S的过程中需要实践操作,首先就是搭建环境
由于babajaja只有两台Linux云服务器,系统分别是CentOs 7.9和Ubuntu 22.04,配置都是2C2G,刚好满足K8S官方要求的最低配置,因两台服务器还属于不同服务商,不在一个局域网内,只能搭建公网环境的K8S集群
目标:安装一套一主节点(CentOs)和一工作节点(Ubuntu)的公网Kubernetes集群
为了在安装过程中了解K8S的组件,以及整体架构;还有为后续学习K8S实操做准备,所以不考虑一键式工具安装。
注:文中但凡出现$your_public_ip,都要替换为对应机器的公网ip
安装kubernetes
安装K8S前置准备
1. 机器环境准备
查看系统信息
lsb_release -a # 可查看系统信息,包括版本代号、发行版描述、发行版 ID、发行版发布号保证两台机器都可以访问外网,以便拉去镜像
保证每台机器的MAC地址和product_uuid都是唯一的
ifconfig # 查看网卡MAC地址
dmidecode | grep UUID # 查看product_uuid,或者用lshw | grep uuid查看2. 关闭防火墙
一般搭建K8S的机器基本在内网,关闭防火墙是为了开放K8S所需的端口,内网的话就不用额外去针对端口每个去放开
所有节点关闭防火墙
sudo systemctl stop firewalld # 停止防火墙
sudo systemctl disable firewalld # 开机不启动防火墙
sudo systemctl status firewalld # 查看防火墙状态是否关闭所有节点关闭SELinux
sudo setenforce 0 # 临时禁用
sudo sed -i --follow-symlinks 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/sysconfig/selinux # 永久禁用SELinux3. 禁止swap分区
原因是内存不足时swap分区会导致io增加,影响应用程序性能,容器的应用程序使用内存是动态变化的,使用swap还会导致其崩溃,所有节点都需禁止
sudo swapon -s # 查看 swap是否启动,有信息打印就是在启动着
sudo swapoff -a # 关闭swap分区,临时的
sudo sed -ri 's/.*swap.*/#&/' /etc/fstab # 注释掉包含swap的行,以永久关闭swap分区4. 时间同步
K8S节点之间时间如果不同步可能会造成一些问题,比如事件的发生顺序混乱、证书验证失败等,所以需要配置一下时间同步
sudo yum install ntpdate -y #安装ntp,ubuntu系统要用apt工具安装
sudo crontab -e #编辑定时任务,设置十分钟同步一次
# 添加下方内容
0-59/10 * * * * /usr/sbin/ntpdate ntp.aliyun.com | logger -t NTP 5. (可选)修改主机名
为了较好的区分机器在K8S集群中的作用,每个节点分别设置对应主机名
sudo hostnamectl set-hostname master
sudo hostnamectl set-hostname node16. (可选)修改hosts
将各个节点的ip地址与主机名映射关系添加到hosts文件中,以便集群中的各个节点可以相互通信,所有节点都修改 hosts
sudo vim /etc/hosts
# 添加下方内容
$ip master #$ip 换成master节点的ip
$ip node1 #$ip 换成node1节点的ip7. (可选)机器做互信
两台机器之间做互信,所有节点都要执行
cd ~/.ssh/
sudo ssh-keygen # 生成密钥
sudo ssh-copy-id -i ./id_rsa.pub root@$ip # $ip是目标机器IP 将私钥发送给互信目标机器,如果ssh端口不是默认22端口,需要加 -p $port 8. 创建虚拟网卡
由于云服务主机内看到的只有内网 IP, 直接搭建会将内网 IP 注册进集群导致搭建不成功
解决方案:使用虚拟网卡绑定公网 IP, 使用该公网 IP 来注册集群(所有节点)(走公网K8S集群才需要做这个操作,内网集群可忽略)
curl ip.sb # 查看机器的公网IP地址
# 临时方法,服务器重启会失效
sudo ifconfig eth0:1 $ip # 所有主机都要创建虚拟网卡,并绑定对应的公网ip $ip 换成机器的公网ip地址永久方法:
CentOs系统
cd /etc/sysconfig/network-scripts # 到网络配置文件目录
sudo cp ifcfg-eth0 ifcfg-eth0:1 # 拷贝eth0网络配置文件
sudo ifcfg-eth0:1添加修改以下内容
DEVICE=eth0:1 # 网卡的设备名称
NAME=eth0:1 # 网卡设备的别名
BOOTPROTO=static # static静态、dhcp动态获取、none不指定(可能出现问题)
ONBOOT=yes # 特别注意 这个是开机启动,需要设置成yes
DNS1=114.114.114.114 # DNS域名解析服务器的IP地址
DNS2=100.100.2.136 # DNS域名解析服务器的IP地址
IPADDR=$your_public_ip # 网卡的IP地址 $your_public_ip替换为你的公网ip
#GATEWAY=192.168.1.1 # 注意:这里设置为空,否则两个网卡同时启用后上不了外网
NETMASK=255.255.255.0 # 子网掩码sudo systemctl restart network # 重新启动网络服务
ip addr show # 查看虚拟网卡是否生效Ubuntu系统
cd /etc/netplan/ # 到网络配置文件目录
sudo cp 50-cloud-init.yaml 50-cloud-init.yaml.bak # 备份下默认文件
vim 50-cloud-init.yaml #编辑网络配置修改一下内容
network:
ethernets:
eth0:
dhcp4: no
addresses:
- 10.1.20.15/22 # 内网ip地址
- $your_public_ip/24 # 添加公网ip地址,主要就是在addresses下添加公网IP地址,$your_public_ip替换为你的公网ip
match:
macaddress: 52:54:00:bf:db:2b
routes:
- to: 0.0.0.0/0
via: 10.1.20.1
nameservers:
addresses:
- 8.8.8.8
- 8.8.8.4
set-name: eth0
version: 2sudo netplan apply # 使配置生效,没有报错即可
ip addr show # 查看虚拟网卡是否生效9. 开通端口
分别在云服务器所在的厂商平台的 控制台-安全组 配置规则,开通K8S的相关端口(走公网K8S集群才需要做这个操作,内网集群可忽略)
master 节点端口

worker 节点端口

所有节点端口
安装Docker
我这边两台机器已安装了最新的docker,就不详细描述了,安装可参考官方文档:所有节点都需安装
安装完docker后,配置一下国内加速源和overlay
sudo mkdir /etc/docker
cat <<EOF > /etc/docker/daemon.json
{
"registry-mirrors": ["https://registry.docker-cn.com","https://nhxqxzjy.mirror.aliyuncs.com"],
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
"storage-driver": "overlay2"
}
EOF
sudo systemctl enable docker # 将docker添加到开机自启
sudo systemctl daemon-reload # 重新加载daemon配置
sudo systemctl restart docker # 重启docker
sudo systemctl status docker # 查看docker运行状态配置和安装K8S
设置网桥参数(所有节点)
如果 Kubernetes 环境的网络链路中走了 bridge 就可能遇到 Service 同节点通信问题,而 Kubernetes 很多网络实现都用到了 bridge。
启用 bridge-nf-call-iptables 这个内核参数 (置为 1),表示 bridge 设备在二层转发时也去调用 iptables 配置的三层规则 (包含 conntrack),所以开启这个参数就能够解决上述 Service 同节点通信问题,这也是为什么在 Kubernetes 环境中,大多都要求开启 bridge-nf-call-iptables 的原因。
overlay 模块用于 Docker 存储驱动,而 br_netfilter 模块则用于实现 Kubernetes 网络功能,这个模块常用于支持网络插件,比如 calico 和 flannel。通过将它们写入配置文件,系统在启动时就会自动加载这些内核模块。
net.ipv4.ip_forward 会启用 IPv4 的数据包转发。
# 将 overlay 和 br_netfilter 写入 /etc/modules-load.d/k8s.conf 配置文件中
cat <<EOF > /etc/modules-load.d/k8s.conf
> overlay
> br_netfilter
> EOF
cat <<EOF > /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
EOF
sysctl --system # 使配置生效添加安装源(所有节点)
CentOs添加阿里云安装源
# 添加 k8s 安装源
cat <<EOF > Kubernetes.repo
[Kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/Kubernetes/yum/repos/Kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=https://mirrors.aliyun.com/Kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/Kubernetes/yum/doc/rpm-package-key.gpg
EOF
mv Kubernetes.repo /etc/yum.repos.d/Ubuntu添加阿里云安装源
curl -s https://mirrors.aliyun.com/Kubernetes/apt/doc/apt-key.gpg | sudo apt-key add - # 添加apt key
echo "deb https://mirrors.aliyun.com/Kubernetes/apt/ Kubernetes-xenial main" >>/etc/apt/sources.list.d/Kubernetes.list #添加安装源安装K8S所需组件(所有节点)
CentOs 安装kubelet、kubectl、kubeadm
sudo yum -y update # 更新yum
sudo yum install -y conntrack ipvsadm ipset jq sysstat curl iptables libseccomp # 安装所需软件
sudo yum install -y kubelet kubeadm kubectl --disableexcludes=Kubernetes # 安装 kubelet、kubeadm 和 kubectl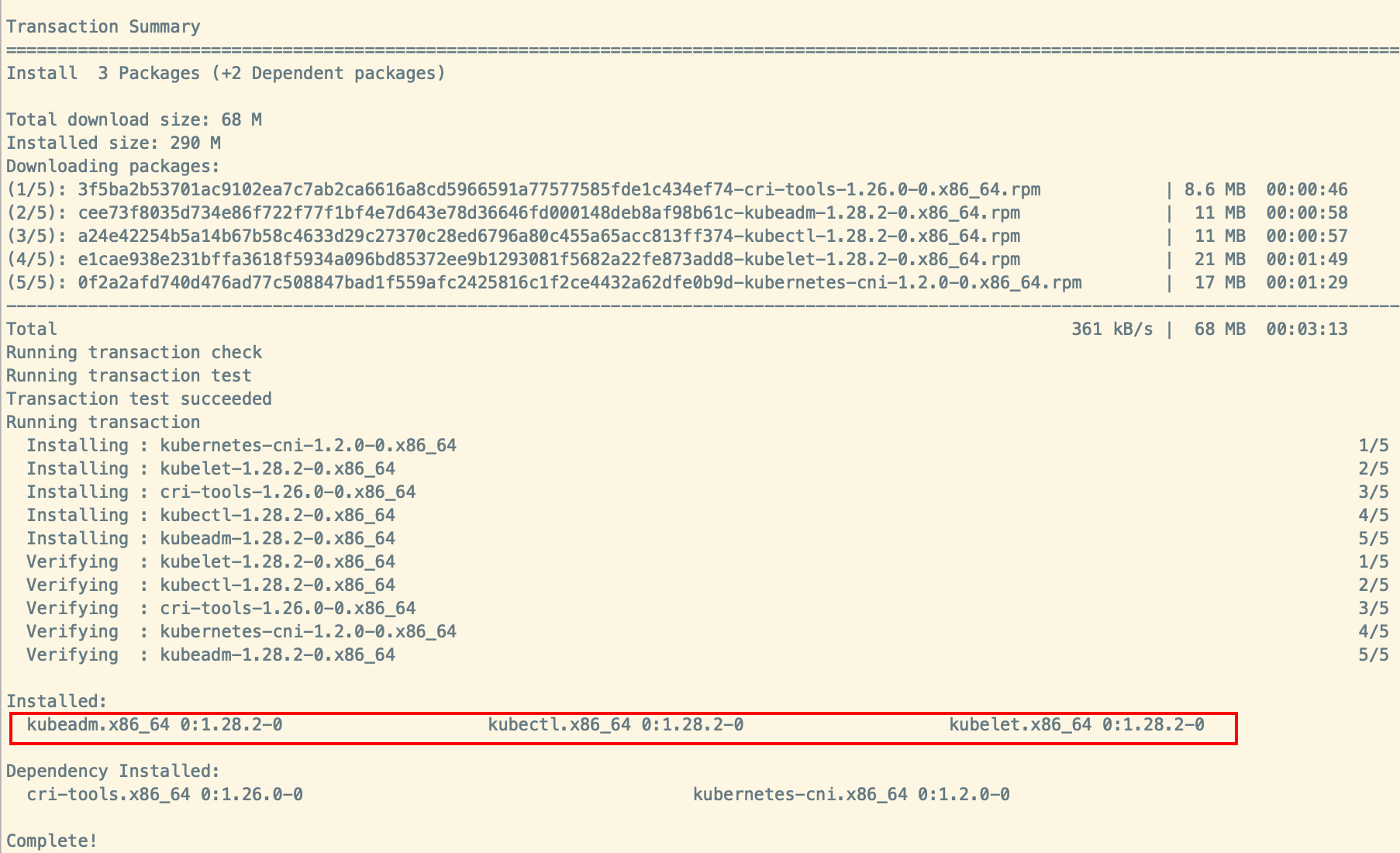
Ubuntu 安装kubelet、kubectl、kubeadm
sudo apt-get update # 更新 apt 包索引
sudo apt install -y apt-transport-https ca-certificates curl # 安装所需软件
sudo apt-get install -y kubelet kubeadm kubectl # 安装 kubelet、kubeadm 和 kubectl
sudo apt-mark hold kubelet kubeadm kubectl # 锁定其版本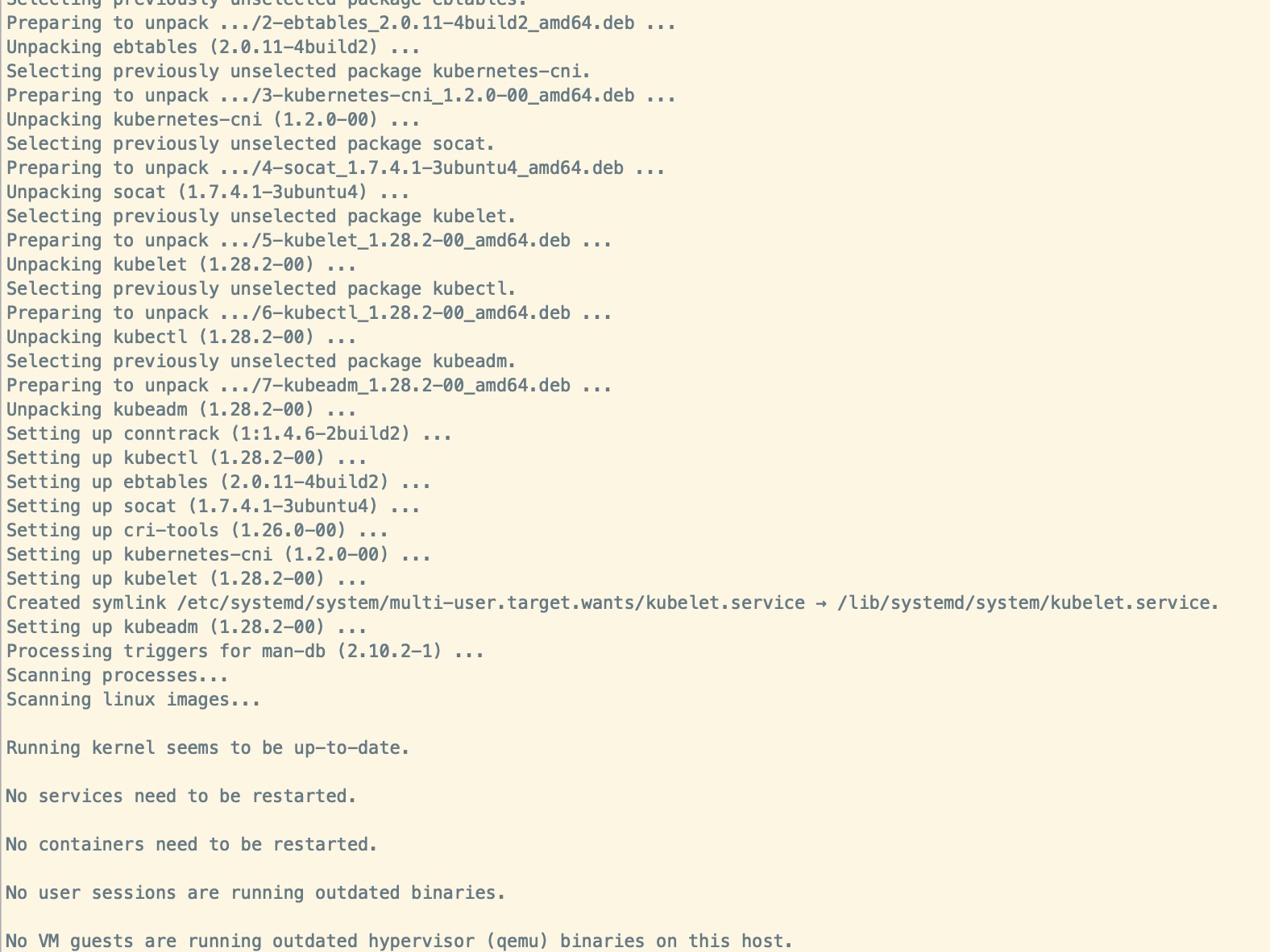
修改 kubelet 启动参数(所有节点)
添加 kubelet 的启动参数--node-ip=公网IP, 每个主机都要添加并指定对应的公网 ip, 添加了这一步才能使用公网 ip 来注册进集群(走公网K8S集群才需要做这个操作,内网集群可忽略)
# Ubuntu 的kubelet配置文件目录
sudo vim /etc/systemd/system/kubelet.service.d/10-kubeadm.conf
# CentOs 的kubelet配置文件目录
sudo vim /usr/lib/systemd/system/kubelet.service.d/10-kubeadm.conf
# 如图 在ExecStart 参数最后添加 --node-ip=公网IP
ExecStart=/usr/bin/kubelet $KUBELET_KUBECONFIG_ARGS $KUBELET_CONFIG_ARGS $KUBELET_KUBEADM_ARGS $KUBELET_EXTRA_ARGS --node-ip=$your_public_ip # $your_public_ip替换为你的公网ip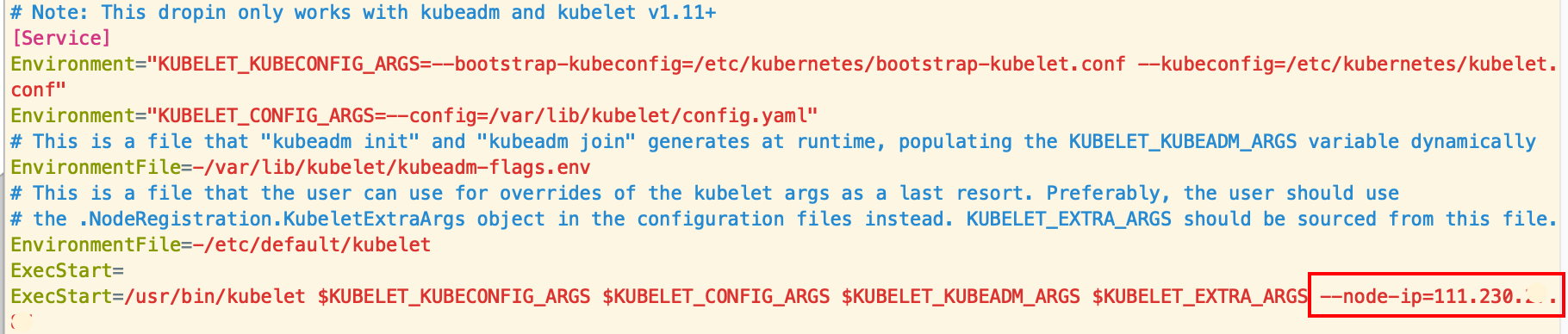
sudo systemctl enable --now kubelet # 启用 kubelet 以确保它在启动时自动启动
sudo systemctl status kubelet.service # 查看kubelet运行状态修改pause镜像安装源(所有节点)
Pause 容器是一种特殊类型的容器,它的主要作用是充当依赖其他容器的容器,为其他容器提供一个可靠的、隔离的运行环境。
查看安装源中pause版本
kubeadm config images list
##输出
I0716 14:31:50.132524 3202474 version.go:256] remote version is much newer: v1.30.2; falling back to: stable-1.28
registry.k8s.io/kube-apiserver:v1.28.11
registry.k8s.io/kube-controller-manager:v1.28.11
registry.k8s.io/kube-scheduler:v1.28.11
registry.k8s.io/kube-proxy:v1.28.11
registry.k8s.io/pause:3.9
registry.k8s.io/etcd:3.5.9-0
registry.k8s.io/coredns/coredns:v1.10.1
可以看出阿里云安装源的pause版本是3.9,kubeadm init 默认配置是拉取 google安装源registry.k8s.io/pase:3.6 ,从而因为网络问题而无法正常拉去导致报错
修改/etc/containerd/config.toml ,修改默认pase 安装源
sudo containerd config default > /etc/containerd/config.toml # 生成 containerd 的配置文件
sudo vim /etc/containerd/config.toml
# sandbox_image = "registry.k8s.io/pause:3.6" # 搜索sandbox_image 注释掉默认的镜像安装源,改为下方的国内安装源
sandbox_image = "registry.aliyuncs.com/google_containers/pause:3.9"systemctl daemon-reload # 重新加载 containerd 配置
systemctl restart containerd.service # 重启 containerd 服务初始化主节点(master节点)
# 初始化集群控制台 Control plane
# 失败了可以用 kubeadm reset 重置
sudo kubeadm init --image-repository=registry.aliyuncs.com/google_containers --kubernetes-version=v1.28.2 --apiserver-advertise-address=$your_public_ip --control-plane-endpoint=$your_public_ip --service-cidr=10.96.0.0/12 --pod-network-cidr=10.244.0.0/16
# $your_public_ip替换为你的公网ip
# 记得把 kubeadm join xxx 保存起来
# 忘记了重新获取:kubeadm token create --print-join-command
# 复制授权文件,以便 kubectl 可以有权限访问集群
# 如果你其他节点需要访问集群,需要从主节点复制这个文件过去其他节点
# 在其他机器上创建 ~/.kube/config 文件也能通过 kubectl 访问到集群看到以下字眼,就是安装成功了
Your Kubernetes control-plane has initialized successfully!
--apiserver-advertise-address string 设置 apiserver 绑定的 IP.
--apiserver-bind-port int32 设置apiserver 监听的端口. (默认 6443)
--apiserver-cert-extra-sans strings api证书中指定额外的Subject Alternative Names (SANs) 可以是IP 也可以是DNS名称。 证书是和SAN绑定的。
--cert-dir string 证书存放的目录 (默认 "/etc/kubernetes/pki")
--certificate-key string kubeadm-cert secret 中 用于加密 control-plane 证书的key
--config string kubeadm 配置文件的路径.
--cri-socket string CRI socket 文件路径,如果为空 kubeadm 将自动发现相关的socket文件; 只有当机器中存在多个 CRI socket 或者 存在非标准 CRI socket 时才指定.
--dry-run 测试,并不真正执行;输出运行后的结果.
--feature-gates string 指定启用哪些额外的feature 使用 key=value 对的形式。
-h, --help 帮助文档
--ignore-preflight-errors strings 忽略前置检查错误,被忽略的错误将被显示为警告. 例子: 'IsPrivilegedUser,Swap'. Value 'all' ignores errors from all checks.
--image-repository string 选择拉取 control plane images 的镜像repo (default "k8s.gcr.io")
--kubernetes-version string 选择K8S版本. (default "stable-1")
--node-name string 指定node的名称,默认使用 node 的 hostname.
--pod-network-cidr string 指定 pod 的网络, control plane 会自动将 网络发布到其他节点的node,让其上启动的容器使用此网络
--service-cidr string 指定service 的IP 范围. (default "10.96.0.0/12")
--service-dns-domain string 指定 service 的 dns 后缀, e.g. "myorg.internal". (default "cluster.local")
--skip-certificate-key-print 不打印 control-plane 用于加密证书的key.
--skip-phases strings 跳过指定的阶段(phase)
--skip-token-print 不打印 kubeadm init 生成的 default bootstrap token
--token string 指定 node 和control plane 之间,简历双向认证的token ,格式为 [a-z0-9]{6}\.[a-z0-9]{16} - e.g. abcdef.0123456789abcdef
--token-ttl duration token 自动删除的时间间隔。 (e.g. 1s, 2m, 3h). 如果设置为 '0', token 永不过期 (default 24h0m0s)
--upload-certs 上传 control-plane 证书到 kubeadm-certs Secret.修改kube-apiserver参数(master节点)
kube-apiserver 添加--bind-address和修改--advertise-addres
--advertise-addres参数是向集群成员通知 apiserver 消息的 IP 地址。 这个地址必须能够被集群中其他成员访问。 如果 IP 地址为空,将会使用 --bind-address, 如果未指定 --bind-address,将会使用主机的默认接口地址
sudo vim /etc/kubernetes/manifests/kube-apiserver.yaml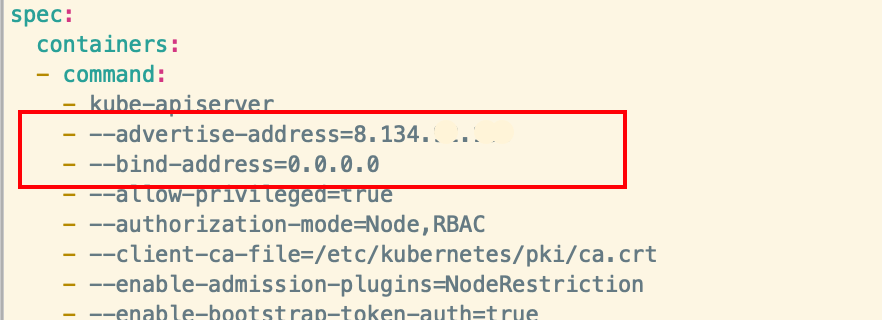
kube-apiserver参数可以查看
安装 flannel 网络(master节点)
下载并修改 flannel 的 yaml 配置文件
wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml # 下载 flannel 的 yaml 配置文件修改 yaml 配置文件
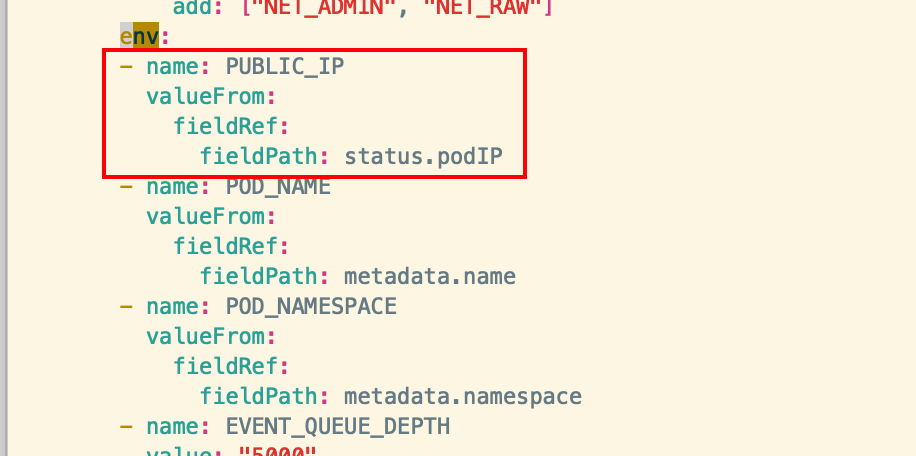
vim kube-flannel.yml 添加两处地方和修改一处地方,分别是配置公网地址PUBLIC_IP 和 pod 的网段地址,需注意缩进对齐
args:
- --public-ip=$(PUBLIC_IP)
- --iface=eth0 env:
- name: PUBLIC_IP
valueFrom:
fieldRef:
fieldPath: status.podIP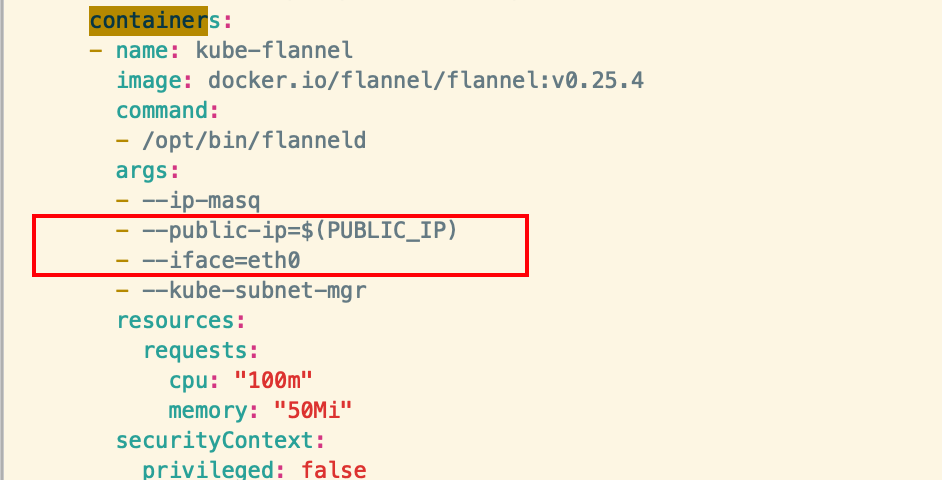
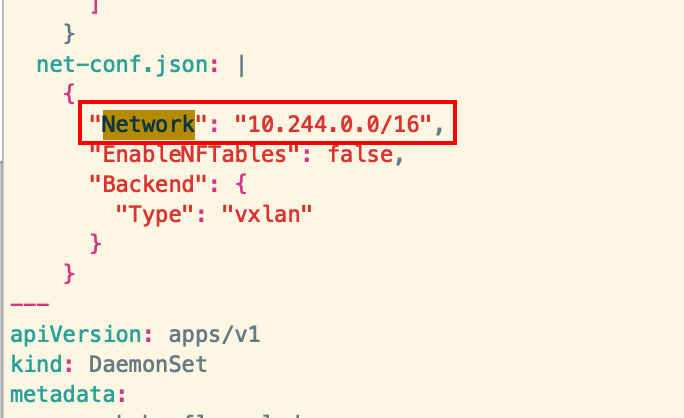
net-conf.json: |
{
"Network": "10.244.0.0/16",
"EnableNFTables": false,
"Backend": {
"Type": "vxlan"
}
}
修改flannel安装源
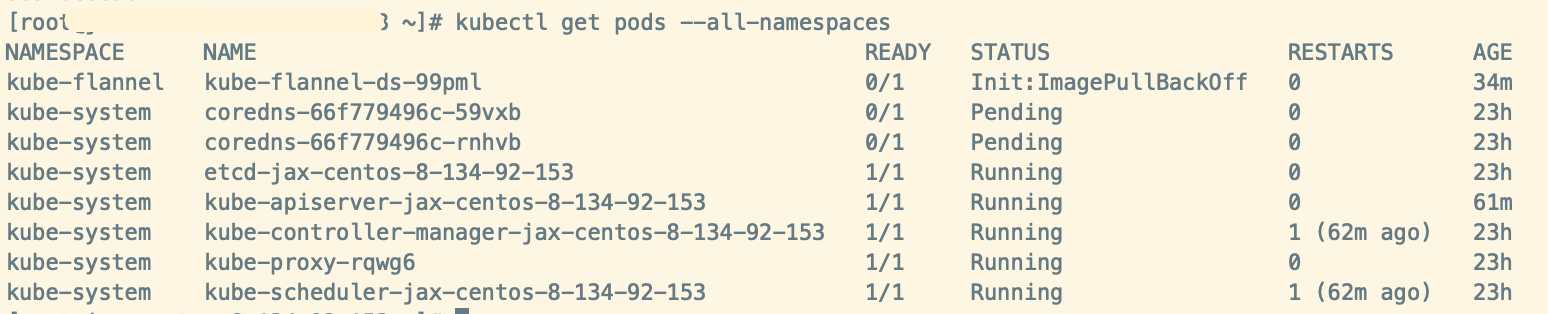
由于kube-flannel.yml 中是默认从docker.io拉取flannel镜像的,国内的服务器大部分无法访问docker.io ,直接执行kubectl apply -f kube-flannel.yml 安装会出现上图情况coredns Pending 状态,kube-flannel init:ImagePullBackOff 状态
处理方法可以是两种:1、将kube-flannel.yml 的flannel镜像安装源改为国内的安装源地址,2、或者手动下载flannel镜像导入到docker中,然后将kube-flannel.yml flannel镜像安装源改为本地docker镜像地址
我用的是将flannel镜像存放在阿里云的容器镜像服务(
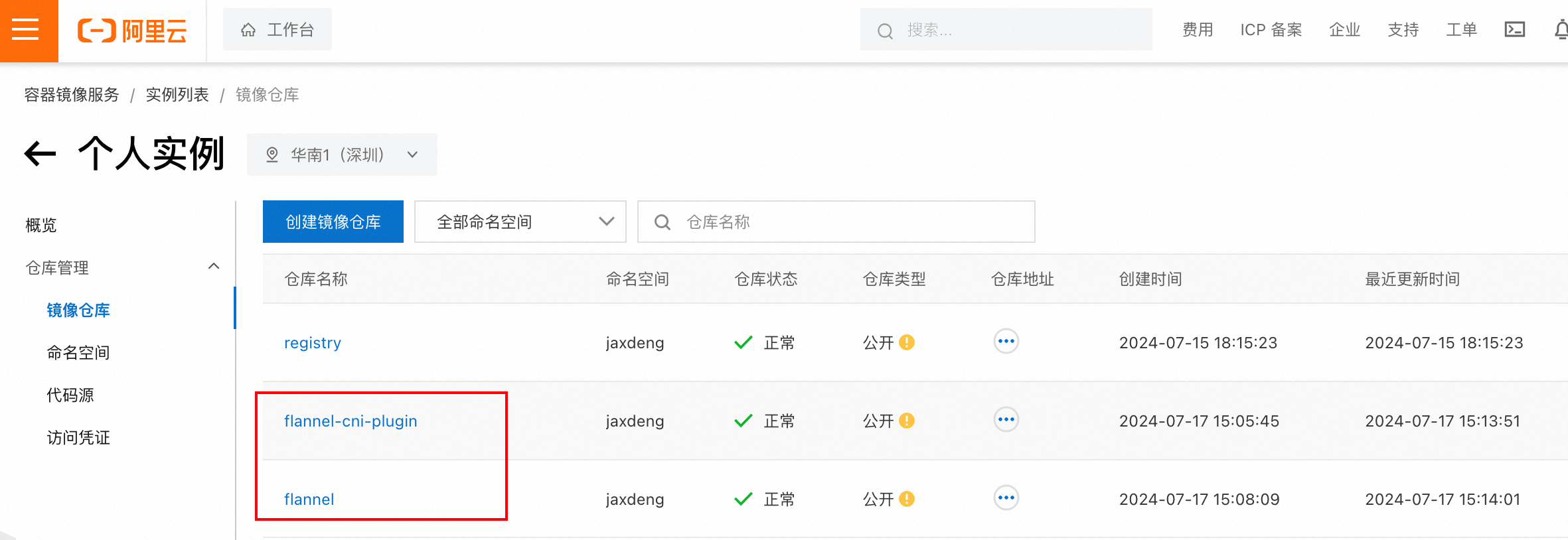
修改 yaml 配置文件
vim kube-flannel.yml 在kube-flannel.yml 文件中搜索image,注释掉默认的image地址,添加为阿里云容器仓库中的flannel和flannel-cni-plugin的镜像源地址
image: registry.cn-shenzhen.aliyuncs.com/jaxdeng/flannel-cni-plugin:v1.5.1-flannel1
image: registry.cn-shenzhen.aliyuncs.com/jaxdeng/flannel:v0.25.4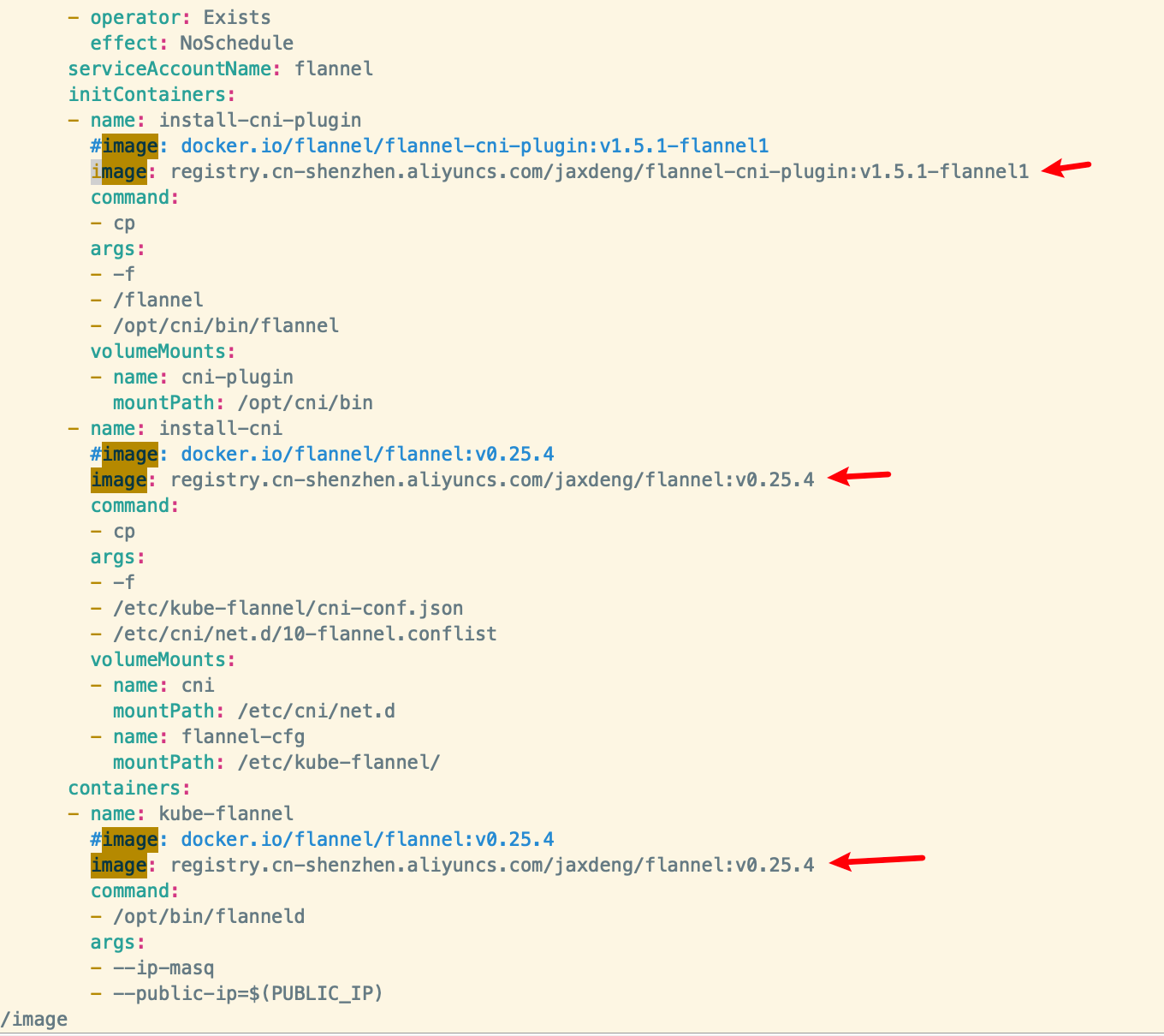
安装flannel网络插件
执行安装命令
kubectl apply -f kube-flannel.yml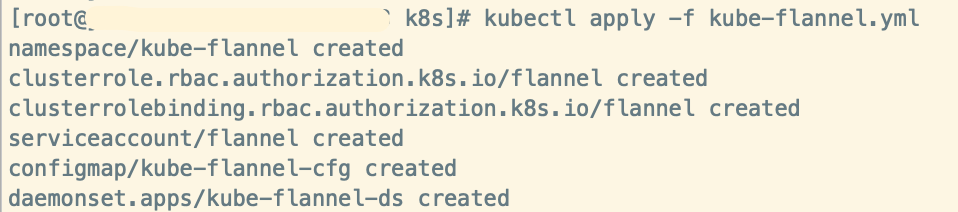
等待一会儿,安装 flannel 网络后,你可以通过在 kubectl get pods --all-namespaces 输出中检查 CoreDNS Pod 是否都是期望的 Running 来确认其正常运行。
kubectl get pods --all-namespaces
worker 节点加入集群
使用初始化 master 节点成功后输出的命令来加入集群,或者在 master 节点重新打印 token 和加入命令
kubeadm token create --print-join-command在 worker 节点执行命令加入集群 $your_public_ip替换为你的公网ip
kubeadm join $your_public_ip:6443 --token xkhpjf.jyzxbdnvrb87yg84 --discovery-token-ca-cert-hash sha256:0936dace8a2582f55b3ebe35626ec13b4b02147d92a9196250b624741c8623fb 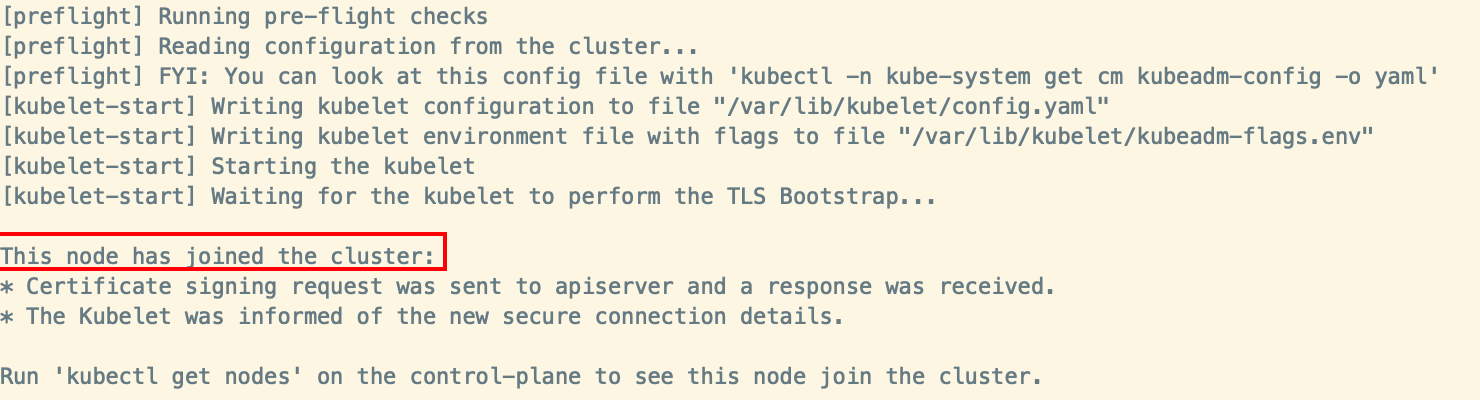
node成功加入后,可以在master执行kubectl get nodes 可以看到已加入的节点,状态都是期望的Ready即是正常
kubectl get nodes
总结
问题记录
Ubuntu apt安装软件完成后提示信息
Created symlink /etc/systemd/system/multi-user.target.wants/kubelet.service → /lib/systemd/system/kubelet.service.
Setting up kubeadm (1.28.2-00) ...
Processing triggers for man-db (2.10.2-1) ...
Scanning processes...
Scanning linux images...
Running kernel seems to be up-to-date.
No services need to be restarted.
No containers need to be restarted.
No user sessions are running outdated binaries.
No VM guests are running outdated hypervisor (qemu) binaries on this host.这个是needrestart软件包的提示,Ubuntu 22.04 默认自带了 needrestart,apt 是集成在一起。在每个 apt 安装完成后都会检查是否有更新,如果有就建议重启。
处理:可忽略
桌面版使用时会有弹窗,直接按 ESC 跳过就好了,并不是强制重启的。
你要是想完全关闭,可以用 apt purge needrestart 卸载掉它。
K8S初始化报错
[init] Using Kubernetes version: v1.28.2
[preflight] Running pre-flight checks
error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR CRI]: container runtime is not running: output: time="2024-07-13T15:37:24+08:00" level=fatal msg="validate service connection: CRI v1 runtime API is not implemented for endpoint \"unix:///var/run/containerd/containerd.sock\": rpc error: code = Unimplemented desc = unknown service runtime.v1.RuntimeService"
, error: exit status 1
[preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...`
To see the stack trace of this error execute with --v=5 or higher处理方法:
/etc/containerd/config.toml
vim /etc/containerd/config.toml
systemctl daemon-reload && systemctl restart containerd && systemctl status containerd # 重新加载配置,重启并查看containerd状态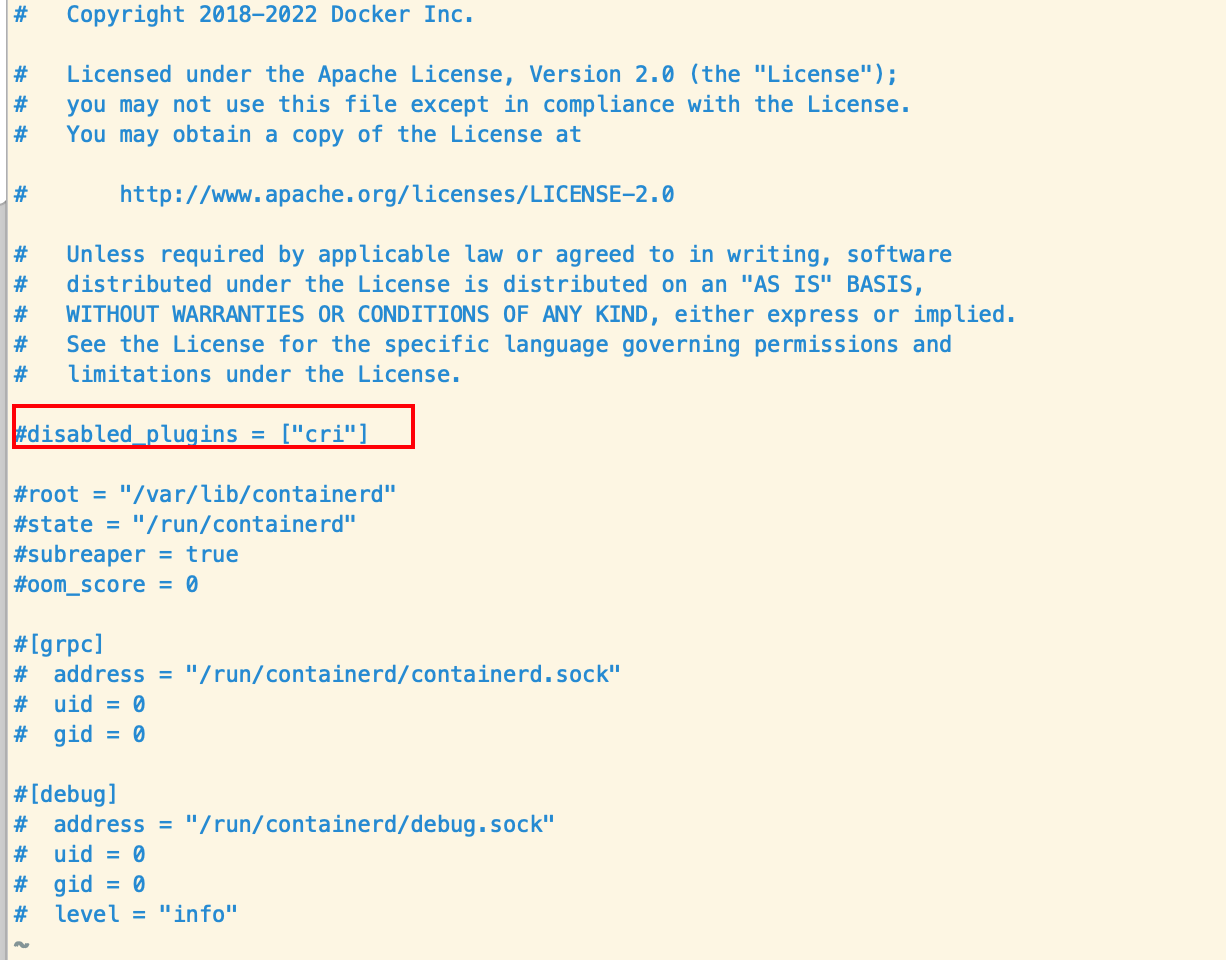
WARN[0000] runtime connect using default endpoints: [unix:///var/run/dockershim.sock unix:///run/containerd/containerd.sock unix:///run/crio/crio.sock unix:///var/run/cri-dockerd.sock]. As the default settings are now deprecated, you should set the endpoint instead.
WARN[0000] image connect using default endpoints: [unix:///var/run/dockershim.sock unix:///run/containerd/containerd.sock unix:///run/crio/crio.sock unix:///var/run/cri-dockerd.sock]. As the default settings are now deprecated, you should set the endpoint instead.
E0713 19:02:57.543772 16950 remote_runtime.go:390] "ListContainers with filter from runtime service failed" err="rpc error: code = Unavailable desc = connection error: desc = \"transport: Error while dialing dial unix /var/run/dockershim.sock: connect: no such file or directory\"" filter="&ContainerFilter{Id:,State:&ContainerStateValue{State:CONTAINER_RUNNING,},PodSandboxId:,LabelSelector:map[string]string{},}"
FATA[0000] listing containers: rpc error: code = Unavailable desc = connection error: desc = "transport: Error while dialing dial unix /var/run/dockershim.sock: connect: no such file or directory" kubeadm init时,拉取k8s.gcr.io/pause:3.6失败
kubeadm init是超时报错
[preflight] You can also perform this action in beforehand using 'kubeadm config images pull'
W0715 18:20:36.084622 3428 checks.go:835] detected that the sandbox image "registry.k8s.io/pause:3.6" of the container runtime is inconsistent with that used by kubeadm. It is recommended that using "registry.aliyuncs.com/google_containers/pause:3.9" as the CRI sandbox image.
.....
[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s
[kubelet-check] Initial timeout of 40s passed.
Unfortunately, an error has occurred:
timed out waiting for the condition
This error is likely caused by:
- The kubelet is not running
- The kubelet is unhealthy due to a misconfiguration of the node in some way (required cgroups disabled)
If you are on a systemd-powered system, you can try to troubleshoot the error with the following commands:
- 'systemctl status kubelet'
- 'journalctl -xeu kubelet'
Additionally, a control plane component may have crashed or exited when started by the container runtime.
To troubleshoot, list all containers using your preferred container runtimes CLI.
Here is one example how you may list all running Kubernetes containers by using crictl:
- 'crictl --runtime-endpoint unix:///var/run/containerd/containerd.sock ps -a | grep kube | grep -v pause'
Once you have found the failing container, you can inspect its logs with:
- 'crictl --runtime-endpoint unix:///var/run/containerd/containerd.sock logs CONTAINERID'
error execution phase wait-control-plane: couldn't initialize a Kubernetes cluster
To see the stack trace of this error execute with --v=5 or higher查看kubelet和CRI containerd日志信息,都会出现以下报错信息
journalctl -xeu kubelet
journalctl -xeu containerd level=error msg="RunPodSandbox for &PodSandboxMetadata{Name:kube-scheduler-jax-centos-8-13
4-92-153,Uid:ad86be6f39869938496ca7bde4edee08,Namespace:kube-system,Attempt:0,} failed, error" error="rpc error: code = DeadlineExceeded desc = failed to get sandbox image \"registry.k8s.io/pa
use:3.6\": failed to pull image \"registry.k8s.io/pause:3.6\": failed to pull and unpack image \"registry.k8s.io/pause:3.6\": failed to resolve reference \"registry.k8s.io/pause:3.6\": failed
to do request: Head \"https://us-west2-docker.pkg.dev/v2/k8s-artifacts-prod/images/pause/manifests/3.6\": dial tcp 64.233.189.82:443: i/o timeout"从报错信息看出是拉取pase:3.6 时超时了
因为kubeadm init 默认会拉取 google安装源registry.k8s.io/pase:3.6 ,从而因为网络问题而无法正常拉去导致报错
修改/etc/containerd/config.toml
sudo containerd config default > /etc/containerd/config.toml # 生成 containerd 的配置文件
sudo vim /etc/containerd/config.toml
# sandbox_image = "registry.k8s.io/pause:3.6" # 注释掉默认的镜像安装源,改为国内的安装源
sandbox_image = "registry.aliyuncs.com/google_containers/pause:3.9"systemctl daemon-reload # 重新加载 containerd 配置
systemctl restart containerd.service # 重启 containerd 服务安装flannel网络插件报错
执行kubectl apply -f kube-flannel.yml 安装会出现如图情况coredns Pending 状态,kube-flannel init:ImagePullBackOff 状态
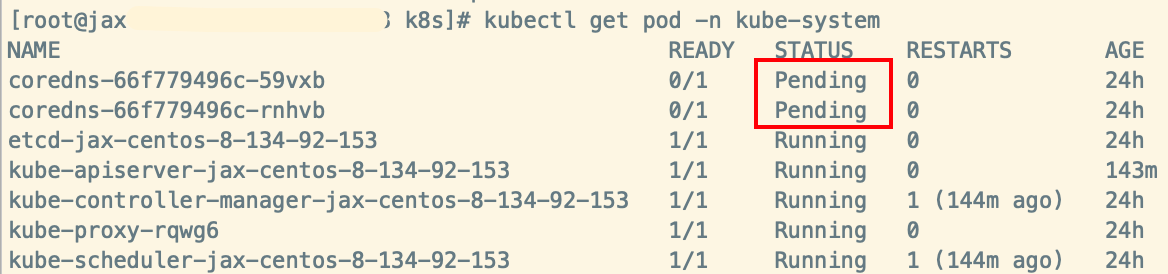
查看kubelet日志
journalctl -xeu kubeletkubelet[4382]: E0716 17:47:51.886056 4382 pod_workers.go:1300] "Error syncing pod, skipping" err="failed to \"StartContainer\" for \"install-cni-plug
in\" with ImagePullBackOff: \"Back-off pulling image \\\"docker.io/flannel/flannel-cni-plugin:v1.5.1-flannel1\\\"\"" pod="kube-flannel/kube-flannel-ds-99pml" podUID="7eaba9b0-f3df-4220-9f87-ae
ae91bc66ab"
kubelet[4382]: E0716 17:47:55.088162 4382 kubelet.go:2855] "Container runtime network not ready" networkReady="NetworkReady=false reason:NetworkPlugi
nNotReady message:Network plugin returns error: cni plugin not initialized"处理方法:看上文 修改flannel安装源
node节点上执行 kubeadm join报错
kubeadm join $your_public_ip:6443 --token xkhpjf.jyzxbdnvrb67yg84 --discovery-token-ca-cert-hash sha256:0936dace8a2582f55b3ebe35626ec13b4b02147d92a1196250b624741c8623fb
[preflight] Running pre-flight checks
error execution phase preflight: couldn't validate the identity of the API Server: could not find a JWS signature in the cluster-info ConfigMap for token ID "xkhpjf"报错信息是没有找到对应的token,可以在master节点上执行kubeadm token list 发现没有token,然后执行kubeadm token create --print-join-command 重新生成一下token即可
kubeadm token list
kubeadm token create --print-join-command
node节点上报错
E0719 15:35:25.878546 2100350 kuberuntime_sandbox.go:72] "Failed to create sandbox for pod" err="rpc error: code = Unknown desc = fai
led to get sandbox image \"registry.aliyuncs.com/google_containers/pause:3.9\": failed to pull image \"registry.aliyuncs.com/google_containers/pause:3.9\": failed to pull and unpack image \"re
gistry.aliyuncs.com/google_containers/pause:3.9\": failed to resolve reference \"registry.aliyuncs.com/google_containers/pause:3.9\": failed to authorize: failed to fetch anonymous token: Get
\"https://dockerauth.cn-hangzhou.aliyuncs.com/auth?scope=repository%3Agoogle_containers%2Fpause%3Apull&service=registry.aliyuncs.com%3Acn-hangzhou%3A26842\": dial tcp [2408:4005:1000:10::2]:44
3: connect: network is unreachable" pod="kube-flannel/kube-flannel-ds-444mw"
kubelet[2100350]: E0719 15:35:25.878583 2100350 kuberuntime_manager.go:1166] "CreatePodSandbox for pod failed" err="rpc error: code = Unknown desc = fa
iled to get sandbox image \"registry.aliyuncs.com/google_containers/pause:3.9\": failed to pull image \"registry.aliyuncs.com/google_containers/pause:3.9\": failed to pull and unpack image \"r
egistry.aliyuncs.com/google_containers/pause:3.9\": failed to resolve reference \"registry.aliyuncs.com/google_containers/pause:3.9\": failed to authorize: failed to fetch anonymous token: Get
\"https://dockerauth.cn-hangzhou.aliyuncs.com/auth?scope=repository%3Agoogle_containers%2Fpause%3Apull&service=registry.aliyuncs.com%3Acn-hangzhou%3A26842\": dial tcp [2408:4005:1000:10::2]:4
43: connect: network is unreachable" pod="kube-flannel/kube-flannel-ds-444mw"
kubelet[2100350]: E0719 15:35:25.878666 2100350 pod_workers.go:1300] "Error syncing pod, skipping" err="failed to \"CreatePodSandbox\" for \"kube-flann
el-ds-444mw_kube-flannel(ee62d20d-ddd6-465e-bd52-205aae501a5c)\" with CreatePodSandboxError: \"Failed to create sandbox for pod \\\"kube-flannel-ds-444mw_kube-flannel(ee62d20d-ddd6-465e-bd52-2
05aae501a5c)\\\": rpc error: code = Unknown desc = failed to get sandbox image \\\"registry.aliyuncs.com/google_containers/pause:3.9\\\": failed to pull image \\\"registry.aliyuncs.com/google_
containers/pause:3.9\\\": failed to pull and unpack image \\\"registry.aliyuncs.com/google_containers/pause:3.9\\\": failed to resolve reference \\\"registry.aliyuncs.com/google_containers/pau
se:3.9\\\": failed to authorize: failed to fetch anonymous token: Get \\\"https://dockerauth.cn-hangzhou.aliyuncs.com/auth?scope=repository%3Agoogle_containers%2Fpause%3Apull&service=registry.
aliyuncs.com%3Acn-hangzhou%3A26842\\\": dial tcp [2408:4005:1000:10::2]:443: connect: network is unreachable\"" pod="kube-flannel/kube-flannel-ds-444mw" podUID="ee62d20d-ddd6-465e-bd52-205aae5
01a5c"
kubelet[2100350]: E0719 15:35:28.824268 2100350 kubelet.go:2855] "Container runtime network not ready" networkReady="NetworkReady=false reason:NetworkP
luginNotReady message:Network plugin returns error: cni plugin not initialized"通过报错可以看出都是网络原因导致的,检查node安装源文件/etc/apt/sources.list.d/Kubernetes.list(ubuntu),发现未配置安装源,
处理方法 配置K8S安装源
参考文档
安装 kubeadm:
公网环境搭建 k8s 集群:
linux 查看product_uuid,即主板id,机器识别码: https://www.cnblogs.com/zhangyy3/p/17021194.html
k8s为什么要禁止swap分区 原创: https://blog.51cto.com/u_15543573/9953381
k8s时间不同步: https://blog.51cto.com/u_15968571/10296705
k8s部署为什么改hosts 原创: https://blog.51cto.com/u_16236295/9391728
为什么 Kubernetes 环境要求开启 bridge-nf-call-iptables ? :https://developer.aliyun.com/article/1273925
如何在CentOS上配置虚拟IP地址 (VIP): https://cloud.tencent.com/developer/article/2147585
Ubuntu 18.04 使用弹性网卡配置多个外网IP: https://cloud.tencent.com/developer/article/1483578
为什么我的 ubuntu22.04 每安装一个软件,就需要重启很多服务?: https://segmentfault.com/q/1010000044233102
搭建k8s集群初始化master节点 kubeadm init 遇到问题解决: https://www.cnblogs.com/wod-Y/p/17043985.html
Kubernetes镜像: https://developer.aliyun.com/mirror/kubernetes/?spm=a2c6h.25603864.0.0.3d6f25c5Wt180D
阿里云开源镜像站: https://developer.aliyun.com/mirror/?spm=a2c6h.25603864.0.0.3d6f25c5Wt180D
评论区